![[python] selenium, chromedriver를 이용한 동적 크롤링으로 카페 정보 수집 실습하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F7MDBl%2Fbtrb8hczcHz%2FAAAAAAAAAAAAAAAAAAAAAM47mKPqsyrIYoyXcib9FzmkfVJIJlTJY0NM1DfxKSfp%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DSxEDhHlECkUg9ni1O3MgIVU5KXc%253D)

안녕하세요!
이전 포스팅에서 bs4를 이용한 정적 크롤링을 포스팅했습니다.
하지만 데이터 수집을 하면서 느낀 점은 다양한 데이터를 수집하는데 한계가 있고
페이지가 동작하여 동적으로 여러 곳에서 데이터를 받아오기 위해 셀레니움을 실습해보려고 합니다.
개발 환경
Language: python 3.9.4
IDE: PyCharm community
Library: selenium
실습하기에 앞서 라이브러리를 먼저 설치해주겠습니다.
pip install selenium
셀레니움을 통한 동적 크롤링을 실습하기 전에 동적 크롤링이 무엇인지 간단하게 알아보기
동적 크롤링은 동적인 데이터를 수집하는 방법을 말합니다.
- 동적인 데이터는 입력, 클릭, 로그인 같이 페이지 이동이 있어야 보이는 데이터를 의미합니다.
- 정적 크롤링보다 수집 속도가 느리지만 더 많은 정보를 수집할 수 있습니다.
사실 키워드는 브라우저를 통한 연속적인 접근이 가능하다는 점이 가장 큰 특징입니다.
| 크롤링 | 정적 크롤링 | 동적 크롤링 |
| 수집 능력 | 주소를 통한 단발적 접근 | 브라우저를 사용한 연속적 접근 |
| 속도 | 빠름 | 느림 |
| 라이브러리 | requests, beautifulsoup | selenium, chromedriver |
크롤링을 하기 전에 확인해야 할 것(robots.txt)

robots.txt
robots.txt는 크롤링 봇이 웹 사이트를 탐색할 때 접근 범위를 제한하기 위해 사용됩니다.
다수의 크롤링 봇이 웹 사이트를 탐색하게 되면 크롤링 봇이 사이트에 과도한 트래픽을 발생시켜
일반적인 다른 사용자가 정상적으로 서비스를 이용하지 못합니다.
따라서 robots.txt 에서 크롤링에 대한 정보를 확인한 후 크롤링 여부를 확인해주시면 됩니다.
크롤링하고자 하는 홈페이지 URL 뒤에 /robots.txt를 추가하여 검색하면 위와 같은 화면이 보입니다.
User-agent: * 는 모든 크롤링 봇을 의미합니다.
Disallow로 표시되어 있는 부분이 크롤링 범위에 제한을 두는 곳이고 탐색하지 말라는 뜻입니다.
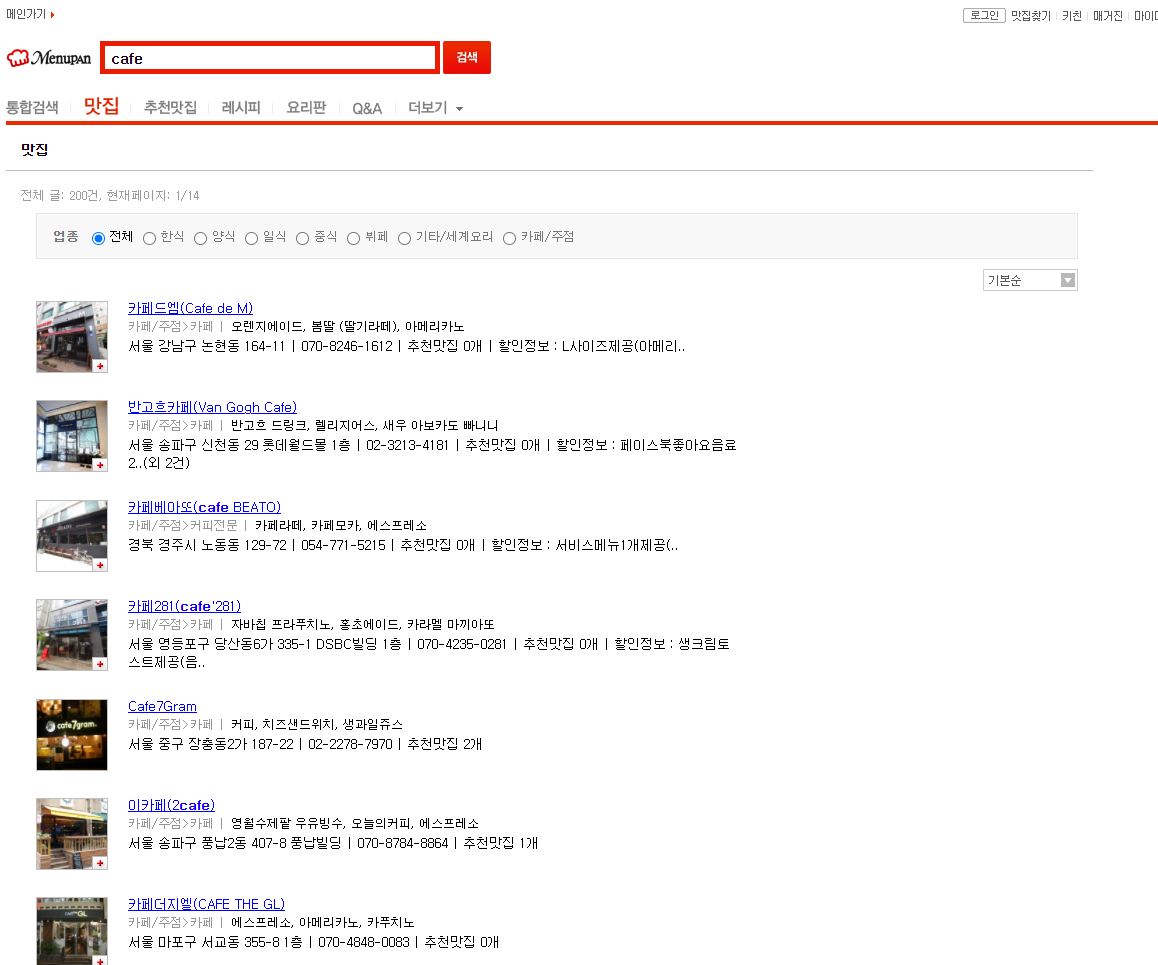
다음과 같은 사이트에서 카페를 클릭하여 카페의 디테일한 정보를 뽑아올 때 사용하면 좋습니다.

앵커 태그를 눌러 디테일 페이지로 넘어왔을 때 화면입니다.
다음과 같이 화면에 보이는 모든 정보를 받아올 때 굉장히 쉽게 받아올 수 있습니다.
크롤링을 하기 위해 크롤링할 데이터의 태그 및 속성을 확인해야 합니다.
크롬 브라우저에서 ctrl + shift + c 를 누르게 되면 요소를 쉽게 선택할 수 있습니다.
크롬 브라우저가 아니시라면 F12 키를 눌러 개발자 도구를 열어서 요소를 탐색해주시면 됩니다.


다음과 같이 요소를 우클릭했을 때 나오는 copy를 통해 css_selector, xpath 등 요소의 경로를 쉽게 따올 수 있습니다.
저기 있는 모든 카페 정보를 받아오기 위해 코드를 작성합니다.
from selenium import webdriver
# 텍스트 정보 크롤링
def text_crawling(selector, dict):
# elements 다중 선택: 찾고자 하는 내용이 없어도 계속 진행
# element 단일 선택: 찾고자 하는 내용이 없으면 NoSuchException 발생,
# 따라서 크롤링 오류 페이지가 있을 시 elements 메서드 사용
if (driver.find_elements_by_css_selector(selector)):
cafe_info_dict[dict].append(driver.find_element_by_css_selector(selector).text)
else:
cafe_info_dict[dict].append(None)
# 이미지 정보 크롤링
def image_crawling():
if (driver.find_elements_by_css_selector('#restphoto_img_6')):
elements = driver.find_elements_by_css_selector('#restphoto_img_6')
# 이미지는 css selector로 뽑아 for문으로 get_attribute를 통해 가져올 수 있음
for i in elements:
image = i.get_attribute('src')
cafe_info_dict['img'].append(image)
else:
cafe_info_dict['img'].append("None")
def crawling():
# 카페 정보 dict
cafe_info_dict = { }
# 찾고자 하는 css selector
selectors = [selector 경로]
# key list 설정
keys = [key 값]
for i in range(1, 271):
# 정상 URL page
URL = 'https://www.menupan.com/search/restaurant/restaurant_result.asp?sc=basicdata&kw=%C4%AB%C6%E4&page=' + str(i)
# 오류 URL page
errorURL = 'https://www.menupan.com/errpage/err_onepage.asp'
# chrome_option
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
# web browser open
driver = webdriver.Chrome(options=chrome_options)
driver.get(url=URL)
for i in range(1, 16):
# NoSuchException 방지를 위한 time.sleep
time.sleep(1)
# a 태그 선택
detailPage = driver.find_element_by_css_selector('ul.listStyle3 > li:nth-child(' + str(i) + ') > dl > dt > a')
time.sleep(1)
# a 태그 클릭하여 detail page로 이동
detailPage.click()
# 현재 url이 오류 페이지 url 일시 close 계속 진행
driver.switch_to.window(driver.window_handles[1])
if (driver.current_url == errorURL):
driver.close()
driver.switch_to.window(driver.window_handles[0]) # 메인 탭으로 이동
# 그게 아니라면 크롤링
else:
# 이미지 크롤링, 텍스트 크롤링 구분
image_crawling()
for i in range(len(keys)):
text_crawling(selectors[i], keys[i])
driver.close()
driver.switch_to.window(driver.window_handles[0])코드를 잠깐 살펴보면 text_crawling과 image_crawling 함수가 따로 만들어져 있는데
text 정보는 selector + text 조합으로 바로 받아지지만 image 정보는 요소의 속성을 받아오기 때문에
요소를 따로 get_attribute를 통해 가져와 주어야 한다.
또한 find_element_css_selector를 사용했을 때 요소를 받아오지 못하면
else문을 수행하지 않고 바로 NoSuchException 예외가 발생한다.
따라서 elements로 처리해주어야 크롤링 중간에 오류 페이지가 섞여있어도 크롤링이 중간에 멈추지 않는다.
time.sleep 역시 크롤링을 하다가 로드되기 전에 요소를 받아오는 경우
NoSuchException이 발생하기 때문에 약간의 텀을 두었다.
그 밖에 click, close, switch_to.window(driver.window_handles[index])로 동적인 처리를 해주고
오류 페이지를 만났을 때 크롤링이 계속 수행될 수 있도록 했다.
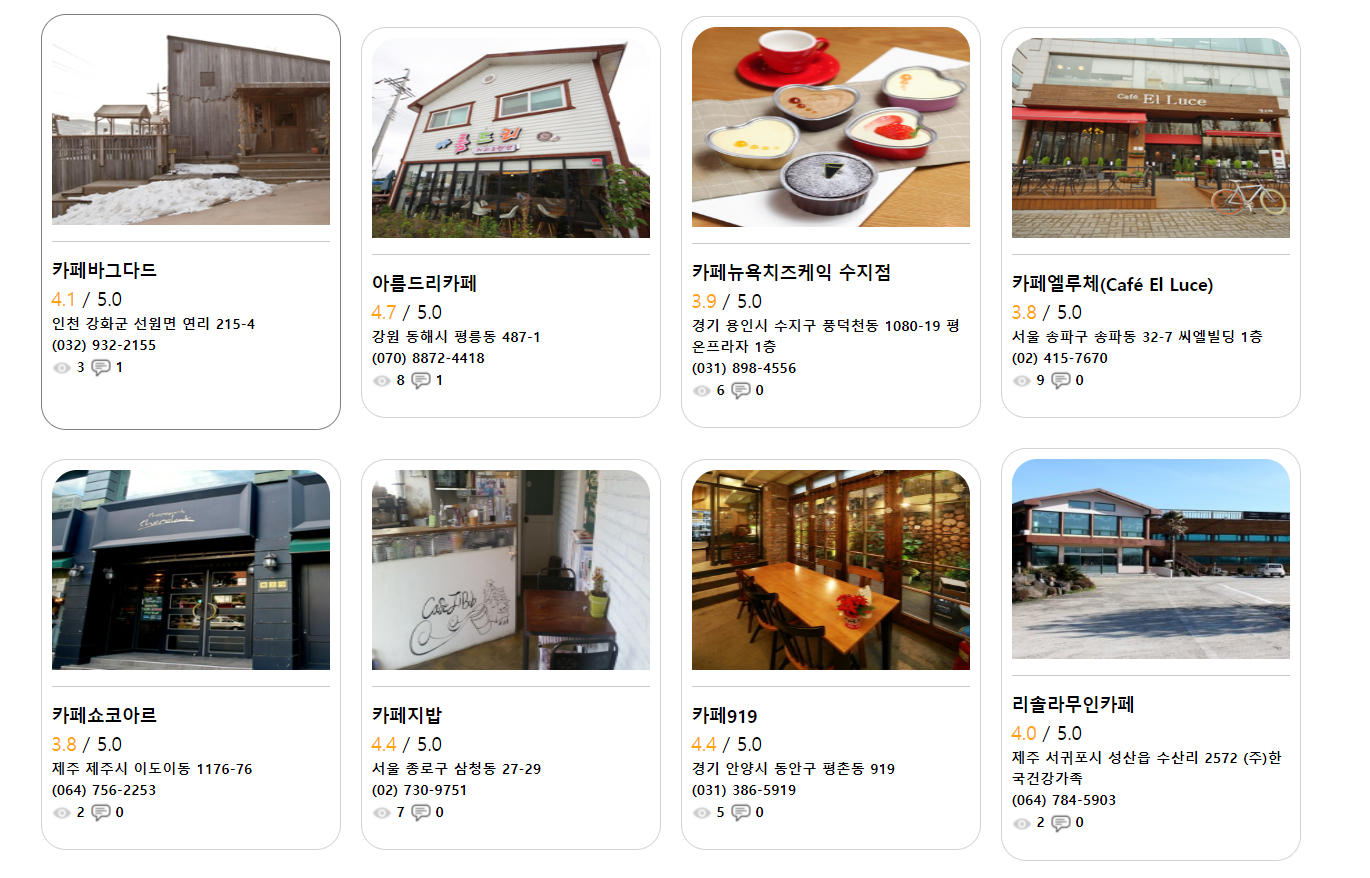
결과

크롤링 결과로 카페의 이미지 주소부터 세부 정보까지 모두 딕셔너리에 담겨서 표시가 된 모습이다.
크롤링된 데이터는 대부분 데이터베이스에 저장되기 때문에 이 데이터를 DB에 저장하게 되면
DB에서 데이터를 꺼내와 사용자에게 보여줄 수 있다.
이렇게 크롤링된 데이터를 DB에 저장해 필터링하여 카페 추천 사이트 프로젝트에 적용할 수 있었다.
이번 시간에는 셀레니움과 크롬 드라이버를 이용해 동적 크롤링을 실습해봤습니다.
고생하셨습니다!
'Programming > Python' 카테고리의 다른 글
| [python] bs4를 이용한 정적 크롤링으로 이미지 저장 실습하기 (1) | 2021.08.15 |
|---|---|
| [Python] requests, beautifulsoup(bs4) 모듈로 강의목록 웹 스크래핑 (0) | 2021.07.06 |
클라우드, 개발, 자격증, 취업 정보 등 IT 정보 공간
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[python] bs4를 이용한 정적 크롤링으로 이미지 저장 실습하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcbIsBk%2Fbtrb7aro62y%2FAAAAAAAAAAAAAAAAAAAAAJu7-uaDW7nFbMqdXCmWufQLEIyjnqv-irClFdQpikWi%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DKjITNPgl9gkz6etbP1y8PQRL4Rk%253D)
![[Python] requests, beautifulsoup(bs4) 모듈로 강의목록 웹 스크래핑](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fb9SPGD%2Fbtq8ZZ6gVBt%2FAAAAAAAAAAAAAAAAAAAAABcVo-Dx6awVpqw0sjCNUMdj3D0oQmHekIztdGNpnqqw%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3Dwg54u1xZd4fChoBeP%252FOmq98cYTM%253D)